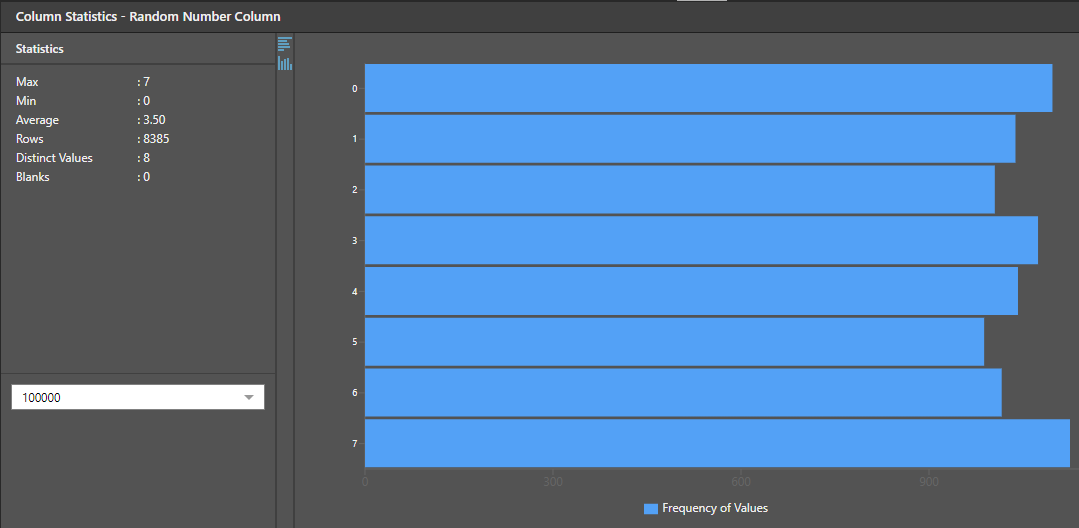
Splitting dataset Train Error
I am trying to spilt dataset into a train and test using Python Node and Learn&Predict.
I get an error below related to pyramid_eval_out.write. How can it be fixed?

Error
PyramidException: scripting error: Scripting process execution for the following command has failed:
E:\Pyramid\python\Scripts\conda run -p E:\Pyramid\repository\general\scripting_Environments\00000000-0000-0000-0000-000000000001 python E:\Pyramid\repository\general\d04da7f0-194d-49d6-b851-de1272dec2ba.py E:\\Pyramid\\repository\\general\\3a19b566-a6ef-41e8-8387-f3ab492d0ca3.csv E:\\Pyramid\\repository\\general\\d559025a-7019-4f2d-b400-bd6def866f0b.txt E:\\Pyramid\\repository\\general\\1b5012da-2f68-4e65-9f34-19823c453e0d.paModel '' E:\\Pyramid\\repository\\general\\57b7beff-b3c8-43c8-ad49-dfb9ae6d4ac0.txt ERROR conda.cli.main_run:execute(41): `conda run python E:\Pyramid\repository\general\d04da7f0-194d-49d6-b851-de1272dec2ba.py E:\\Pyramid\\repository\\general\\3a19b566-a6ef-41e8-8387-f3ab492d0ca3.csv E:\\Pyramid\\repository\\general\\d559025a-7019-4f2d-b400-bd6def866f0b.txt E:\\Pyramid\\repository\\general\\1b5012da-2f68-4e65-9f34-19823c453e0d.paModel '' E:\\Pyramid\\repository\\general\\57b7beff-b3c8-43c8-ad49-dfb9ae6d4ac0.txt` failed. (See above for error) Traceback (most recent call last): Pyramid Script, line 97, in <module> __pyramid_eval_out.write(__pyramidEval) TypeError: write() argument must be str, not None
6 replies
-
Hi Ilya. The direct cause of the error you are getting is that pyramid_eval function returns None while it supposed to return a string. I can't see the pyramid_eval function in the post, I only see pyramid_learn, but if you didn't change the default code then the functions only has the templated comments and no actual code that does evaluation, so the return value is therefore None.
I recommend using the marketplace icon (next to the Learn & Predict Script dropdown) to select a real script with implementation, like KNN. Then the script will be operational, and you'll be able to modify it to fit your specific needs.
Hope that helps. If it's still not working, please copy paste to the post the whole script so I could help you with it more efficiently. -
Please select python environment variable